In a significant development poised to reshape the landscape of artificial intelligence, Google has unveiled a groundbreaking technology called TurboQuant. This innovative compression algorithm promises to dramatically enhance the efficiency of large language models (LLMs) by substantially reducing their memory footprint while simultaneously boosting performance, all without compromising accuracy. The announcement has already sent ripples through the memory chip market, highlighting the profound implications of this advancement for the future of AI development and deployment.
Unpacking Google’s TurboQuant: A Technical Marvel
At its core, TurboQuant is a sophisticated two-stage compression method designed to optimize the key-value (KV) cache in LLMs. The KV cache is a critical component that stores information for efficient retrieval during AI model inference. By making this cache significantly more compact, TurboQuant addresses one of the most pressing bottlenecks in scaling large AI models.
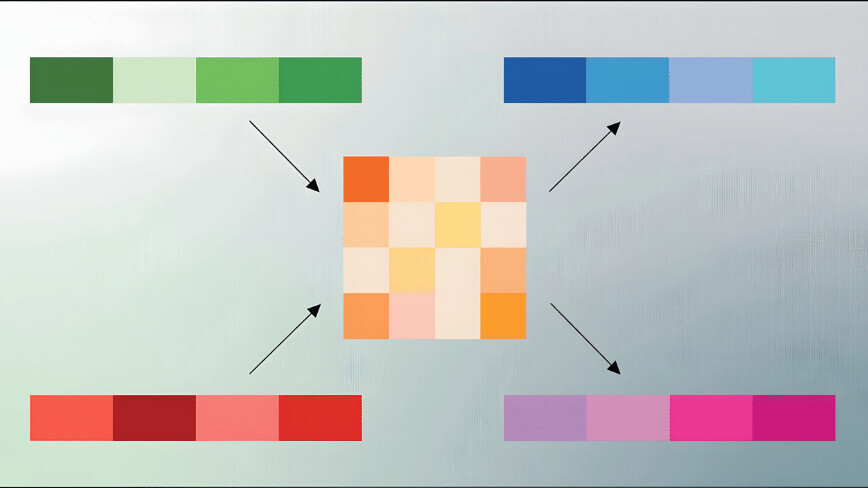
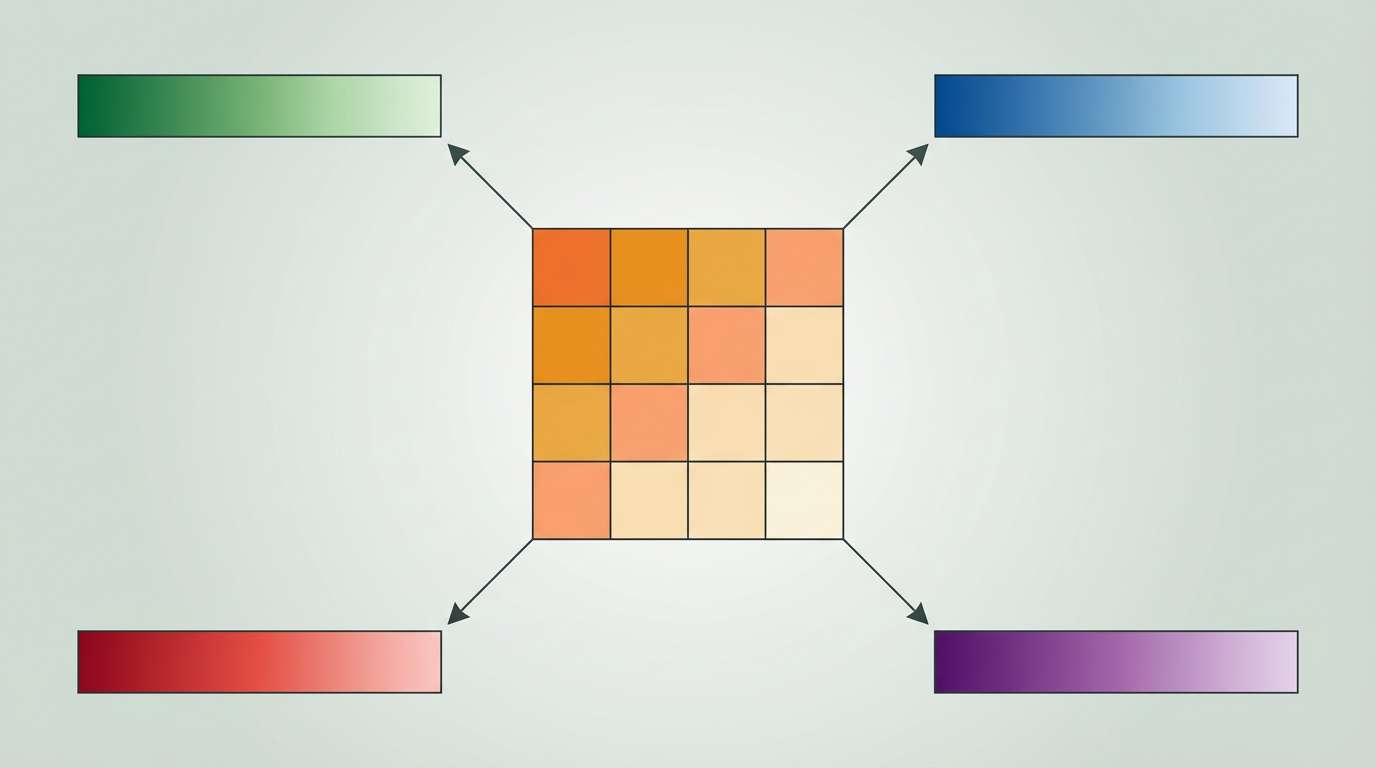
The first stage of TurboQuant, known as PolarQuant, employs a high-quality compression technique that involves randomly rotating data vectors. This process simplifies the data’s geometry, allowing for the application of a standard quantizer to each vector part. This initial step captures the main concept and strength of the original vector, utilizing the majority of the compression bits.
The second stage focuses on eliminating hidden errors. It applies the Quantized Johnson-Lindenstrauss (QJL) algorithm to the residual error from the first stage, using just one bit of compression power. This mathematical error-checking mechanism removes bias, leading to a more accurate attention score within the LLM.
Performance and Market Impact
Google’s research indicates that TurboQuant can reduce the memory required to run large language models by at least a factor of six. This substantial reduction in memory usage translates into significant cost savings for training and deploying AI models. Furthermore, TurboQuant has demonstrated impressive speedups, achieving up to an 8x performance increase in computing attention logits on Nvidia H100 GPU accelerators when using 4-bit TurboQuant compared to 32-bit unquantized keys.
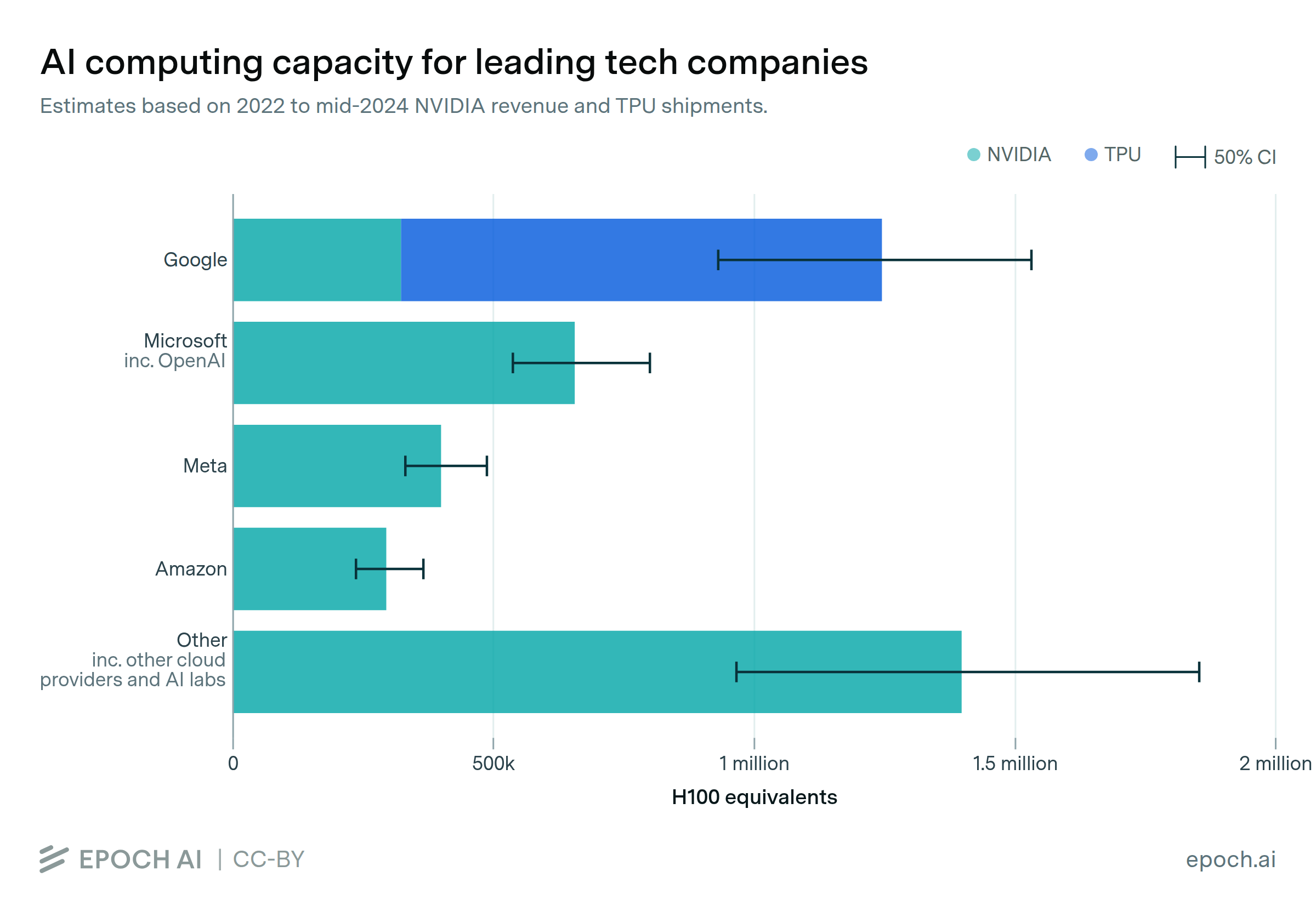
The announcement of TurboQuant has had an immediate effect on the memory chip market, with stocks of major players like SK Hynix Inc and Samsung Electronics Co experiencing declines. Investors are concerned that the increased efficiency brought by TurboQuant could reduce the demand for high-bandwidth memory, which has been a key driver of growth in the chip industry due to the rapid expansion of AI infrastructure.
The Jevons Paradox in AI
Despite initial market jitters, some analysts suggest that the long-term impact of TurboQuant might align with the Jevons Paradox. This economic theory posits that increased efficiency in resource use can lead to an overall increase, rather than a decrease, in demand for that resource. In the context of AI, a lower cost per token and more efficient model deployment could spur greater adoption and more complex AI applications, ultimately leading to a sustained or even increased demand for underlying hardware, albeit with different specifications.
TurboQuant: Key Features and Benefits
| Feature | Description | Benefit |
|---|---|---|
| Memory Reduction | Reduces KV cache memory by ≥6x | Lower operational costs, ability to run larger models |
| Performance Boost | Up to 8x faster attention computation | Faster AI inference, improved responsiveness |
| Accuracy | Zero accuracy loss | Reliable model performance, no compromise on output quality |
| Compression Method | Two-stage (PolarQuant & QJL) | High-quality and error-free compression |
| Implementation | Efficient, negligible runtime overhead | Easy integration into existing AI workflows |
Conclusion
Google’s TurboQuant represents a significant leap forward in AI efficiency. By tackling the memory bottleneck in large language models without sacrificing accuracy, it paves the way for more powerful, cost-effective, and widespread AI applications. While the immediate market reaction has been cautious, the long-term implications suggest a future where AI capabilities are further democratized and integrated into various industries, potentially driving new waves of innovation and demand.
Focus Keyphrase: Google TurboQuant
Meta Description: Discover Google’s TurboQuant, a revolutionary AI compression algorithm that reduces LLM memory by 6x and boosts performance by 8x with zero accuracy loss, reshaping the future of AI.






{kind=link}